Zur Unterstützung von Anwendern und Netzwerkern wurde ein Tool zur Online- Beobachtung des Netzwerk-Datenverkehrs von Metacomputing-Anwendungen entwickelt. Mit den so gemessenen Verkehrsprofilen kann der Verlauf der PACX-MPI-Anwendungen analysiert werden.
Voraussetzung für die meisten Metacomputing-Anwendungen ist eine ausreichend schnelle Übertragung von Daten. Begrenzende Faktoren sind dabei die zum Zeitpunkt der Anwendung auf allen beteiligten Netzstrecken zur Verfügung stehende minimale Bandbreite und die Latenzzeit (allein das Licht benötigt ca. 20 ms über den Atlantik).
Die Messung des Netzverkehrsprofils einer Metacomputing-Anwendung kann hier Schwachstellen und Verbesserungsmöglichkeiten aufdecken helfen. Im Rahmen der PACX-MPI-Anwendungen zwischen Pittsburgh und dem RUS wurde der momentane Datenverkehr auf der dedizierten transatlantischen ATM-Verbindung über die Zellenzähler ciscoAtmVclIn- und -OutCells der Cisco-ATM-CONN-MIB auf einem Cisco-Atm-Switch für den zugehörigen VPI/VCI abgefragt.
Mittels einer graphischen Darstellung durch ein Applet ist der aktuelle
Leitungsverkehr über das World Wide Web von überall abrufbar.
Damit erhalten Netzwerk-Manager und Anwender eine schnelle visuelle Darstellung
des Zustands der Leitung, was insbesondere bei Verbindungen über mehrere
Netzwerke hinweg und bei Online-Demonstrationen, wie auf der SC `97, aber
auch beim Debuggen und Optimieren während der Anwendungsentwicklung
nützlich ist.
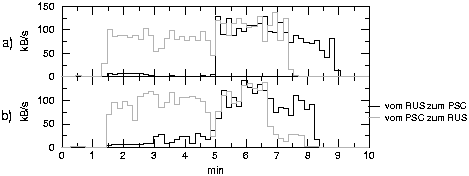
Das Verkehrsprofil spiegelt den Programmablauf wider. Nach dem Start des URANUSProgramms auf der T3E in Pittsburgh erfolgt eine kurze Initialisierungsphase ohne Da-tenverkehr. Dann werden die Anfangsdaten, ca. 17 MB, von der T3E am PSC zur T3E ans RUS geschickt (gestrichelte Linie) und es fließen nur wenige Daten zurück (durchgezogene Linie). Nach Erhalt der Anfangsdaten beginnt die eigentliche Berechnungsphase mit regem Datenaustausch zwischen den Prozessoren in beiden Richtungen. Nach Abschluß der Rechnungen werden die Ergebnisse vom Startprozessor gesammelt, d.h. der Netzverkehr verläuft einseitig in Richtung PSC.
Die Berechnungsphase beginnt hier erst, nachdem die gesamten Anfangsdaten auf die verschiedenen Prozessoren verteilt wurden. Abbildung 1b zeigt das Verkehrsprofil einer Programmversion, bei der die Knoten sofort nach Erhalt ihrer jeweiligen Anfangsdaten mit der Rechnung beginnen können. Entsprechend fließen schon früher Daten in beide Richtungen. Am Programmende haben die ersten Knoten ihre Rechnung bereits abgeschlossen und versenden ihre Ergebnisse, während die später gestarteten noch rechnen. Die Prozessoren und das Netz sind insgesamt besser ausgelastet, wodurch die Latenzzeit verringert wird und die Gesamtrechenzeit für einen Programmlauf sinkt.
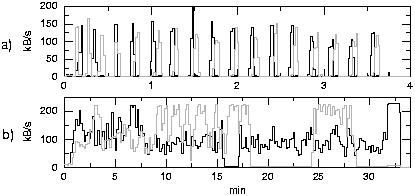
Anders stellt sich das Verkehrsprofil des Testlaufs einer Direct Simulation
Monte Carlo (DSMC)-Simulation dar. Dieses ist in Abbildung 2a dargestellt,
wobei der Netzverkehr in Sekundenschritten gemessen wurde. Hier müssen
am Anfang und Ende der Simulation keine großen Datenmengen übertragen
werden. Die verschiedenen Prozessoren berechnen ihr jeweiliges Teilchenkontingent
für eine bestimmte Zeit unabhängig voneinander. Erst nach Ablauf
eines Rechenschrittes werden Daten verschickt. Die Verkehrsmessungen zeigen
entsprechend abwechselnd Zeiten des Datenaustauschs und Zeiten, während
derer kein Byte übertragen wird.
Dr. Ingo Seipp, NA-5988
E-Mail: seipp@rus.uni-stuttgart.de