Die Leistungsmerkmale von Supercomputern wie Rechengeschwindigkeit, Hauptspeicherausbau und Datentransfergeschwindigkeit werden beständig verbessert. Ein Zeichen für diese Entwicklung sind die immer größeren Probleme, die man mit diesen Rechnern behandeln kann, wie es sich unter anderem in der Entwicklung von Weltrekorden zeigt.
Bisher waren diese Weltrekorde im wesentlichen Ausdruck der Leistungsfähigkeit der zu diesem Zeitpunkt größten Computer. Heute versucht man darüberhinaus, die Re-chenleistung noch weiter zu steigern, indem man solche Supercomputer zu Metacomputern verbindet. Das Höchstleistungsrechenzentrum der Universität Stuttgart (HLRS) kooperiert in diesem Zusammenhang mit den Sandia National Laboratories (SNL) und dem Supercomputing Center in Pittsburgh (PSC).
| 1.0 * 10^9 | 1996 | E. D'Azevedo
C. Romine |
Oak Ridge National Laboratory |
| 1.2 * 10^9 | März 1997 | J. Stadler | ITAP, Universität Stuttgart |
| 1.4 * 10^9 | November 1997 | M. Müller | ICA1, Universität Stuttgart |
Am 19. und 20. November wurde ein weiterer Meilenstein des Metacomputing gesetzt, als diese Simulationsprogramme gleichzeitig auf der CRAY T3E der Universität Stuttgart und der CRAY T3E am Supercomputing Center von Pittsburgh gestartet wurden.
Sowohl die Simulation eines FCC-Kristalls von 1.399.440.000 Atomen mit Molekulardynamik und eines granularen Gases von 1.759.165.695 Teilchen mit Direct Simulation Monte Carlo stellen einen Weltrekord dar.
Die Molekulardynamik benutzte die Verlet-Integrationsmethode mit Linked Cell-Algorithmus, Lennard Jones-Wechselwirkung und 2.5 ä Abschneideradius.
Beide Programme verwenden P3T, ein objektorientiertes Design für Teilchensimulationen, das am ICA1 entwickelt wird. Kernstück der beiden Programme ist ein paralleler Template Container. Dieser verwaltet die Teilchen und ist für die Kommunikation mittels MPI zuständig. Der Container stellt einen lokalen Ausschnitt des Gesamtsystems auf jedem Prozessor zur Verfügung.
Die Zeitschleife für die Integration der Bewegung sieht im Fall der Molekulardynamik folgendermaßen aus:
while( t<maxT){
//distributes and updates particle data on processors:Der Benutzer des Containers sieht praktisch keinen Unterschied zwischen einem Einprozessor- und einem Parallelrechner.box.update();
//force and potential energy calculations:
box.for_each_pair(myForce);
for_each_particle(box.begin(),box.end(),myIntegrator);
t+=dt;
}
Falls Latency Hiding erforderlich ist, muß der Code allerdings
angepaßt werden:
Der Aufruf von update() wird getrennt in update_init()
und update_wait().
Nach dem ersten Aufruf können Berechnungen mit lokalen Teilchen durchgeführt werden, während im Hintergrund die Kommunikation abläuft. Nach Beendigung von update_wait() können dann auch die Teilchen am Rand für Berechnungen verwendet werden.
Da die externe Kommunikation zwischen Rechnern um mehrere Größenordnungen
langsamer ist als die interne Kommunikation, macht erst dieses Latency
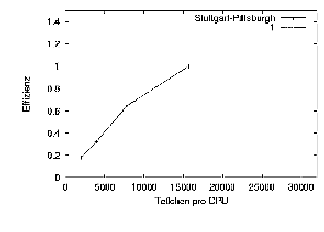
Hiding den Einsatz im Rahmen des Metacomputing sinnvoll. In Abb. 1 sieht
man, daß es bei genügend großen Teilchenzahlen möglich
ist, die Latenzzeiten vollständig zu verstecken. Das heißt bei
geeignetem Verhältnis von Kommunikations- zu Rechenaufwand muß
das Programm nicht mehr auf eintreffende Nachrichten warten. Bei großen
dreidimensionalen Systemen wird jedoch die Zeitdauer der Kommunikation
durch die Bandbreite bestimmt. So wurde beispielsweise die MD-Simulation
mit 1.4 Milliarden Teilchen durch die 2 MBit-Leitung deutlich gebremst.
Nachdem mit den beiden Weltrekorden die technische Durchführbarkeit des Metacomputing demonstriert wurde, ist die nächste Herausforderung der weitere Einsatz bei wissenschaftlichen Fragestellungen, für die so große Systeme notwendig sind, daß die erforderlichen Ressourcen nur über Rechnerverbände bereitgestellt werden können.
Matthias Müller / ICA 1, NA-7606
E-Mail: matthias@ica1.uni-stuttgart.de