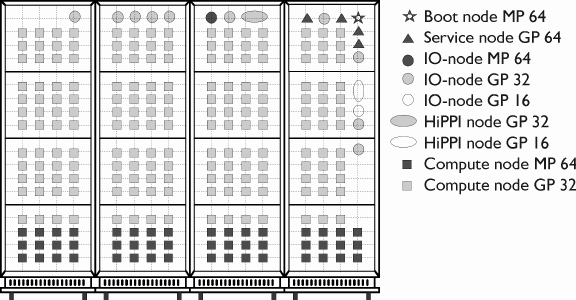
Paragon XP/S:
Zusammenführung von HLRS und FZ-Jülich
Bernd Krischok
Im Dezember 1992 wurde an der Universität Stuttgart erstmals ein massiv-paralleles System, eine intel Paragon XP/S-5, gemeinsam von RUS, IPVR und ICA II installiert. Dieses Pathfinder System erwies sich als ideale Plattform für die Entwicklung portabler Software.
Nach der Installation der wesentlich leistungsstärkeren CRAY T3E entschied man sich für den Weiterbetrieb der Paragon, da die CRAY T3E für die Programmentwicklung aufgrund des Betriebsmodells nur sehr eingeschränkt einsetzbar ist. Man erweiterte das System im Herbst 1996 um 41 Multi Prozessor (MP)-Knoten zu einer Paragon XP/S-5+ mit 113 Compute-Knoten. Aufgrund einer Vereinbarung mit dem Forschungszentrum Jülich wurde Ende Juli 1998 die Stuttgarter und die Jülicher Paragon an einem Standort zu einem System XP/S-15+ mit 228 Knoten zusammengeführt. Trotz der heutzutage geringen Leistung von 75 MFLOPS/CPU und 32/64 MByte Hauptspeicher/Knoten, soll die Paragon wegen Ihres flexiblen Betriebsmodells und den geringen Kosten den Benutzern weiter eine ideale Entwicklungsumgebung für parallele Programmierung bieten.
Hardware-Erweiterungen
Bis Juni 1998 standen den Benutzern der intel Paragon am RUS 72 General Purpose (GP)-Knoten und 41 Multi Prozessor (MP)-Knoten [1, 2, 3] in der .compute-Partition für parallele Anwendungen zur Verfügung. MP-Knoten besitzen 3 i860XP Prozessoren [1], GP-Knoten nur 2 solcher CPUs. Außerdem besitzen diese Knoten in der .compute-Partition 64 MByte Hauptspeicher statt 32 MByte bei den GP-Knoten. Wie diese MP-Knoten genutzt werden können, findet man in [3] und [4].
Im Juli 1998 wurde das System auf insgesamt 246 Knoten erweitert. Für parallele An-wendungen stehen dem Benutzer davon nun 228 Knoten zur Verfügung. 180 Stück sind GP-Knoten mit 32 MByte und 48 sind MP-Knoten mit 64 MByte Hauptspeicher. Zusätzlich wurde das System um 6 RAIDs erweitert, so daß insgesamt 13 RAIDs mit zusammen 64 GByte Plattenplatz verfügbar sind. Den Benutzern stehen davon 41.5 GByte in den HOME-Verzeichnissen und 8.5 GByte im parallelen Filesystem (PFS) zu. Dies entspricht mehr als einer Verdoppelung des Plattenplatzes.
Das PFS ist auf 11 IO-Knoten statt auf 5 IO-Knoten verteilt und sollte entsprechend schneller geworden sein. Die theoretische Spitzenleistung eines i860XP-Prozessors liegt bei 75 MFLOPS [1]. Einer der Prozessoren eines Knotens wird für das Message Passing benötigt. Die übrigen CPUs stehen dem Benutzer für Anwendungen zur Verfügung. Damit liegt jetzt die theoretische Spitzenleistung der Paragon in der .compute-Partition bei 20.7 GFLOPS (276 CPUs x 75 MFLOPS). Dies entspricht nahezu einer Verdoppelung der bisherigen Rechenleistung. Zu beachten ist jedoch, daß der dritte Prozessor in einem MP-Knoten keine Arbeit verrichtet, wenn der Benutzer in seinen Programmen nicht die dafür nötigen Maßnahmen ergreift [3, 4]. Ohne solche Maßnahmen verhalten sich die MP-Knoten wie GP-Knoten mit 2 CPUs und die theoretisch erreichbare Spitzenleistung der Paragon liegt nur bei 17.1 GFLOPS (228 CPUs x 75 MFLOPS.
Abbildung 1 zeigt die neue Hardware-Konfiguration der Paragon.
Überblick der Leistungssteigerungen des Systems
| Dezember 1992 | Oktober 1996 | Juli 1998 | |
| Knotenzahl des Gesamtsystems | 84 | 126 | 246 |
| Knoten in .compute Partition: GP / MP | 72 / - | 72 / 41 | 180 / 48 |
| Peak Performance | 5,4 GFLOPS | 11,6 GFLOPS | 20,7 GFLOPS |
| Memory des Systems | 2,3GB | 4,8 GB | 8,6 GB |
| Users Disk Space | 14,4GB | 20,3 GB | 50 GB |
| Cabinets | 2 | 2 | 4 |
An der Universität Stuttgart wird die Paragon abhängig von der Tageszeit in zwei unterschiedlichen Betriebsweisen gefahren. 24-Stunden (auch an Wochenenden) interaktiver Betrieb auf allen 228 Knoten der .compute Partition. Batch Jobs laufen nur, wenn die verwendeten Knoten nicht von interaktiven Jobs gebraucht werden. Zwischen 07:30 und 20:30 Uhr starten keine neue Batch Jobs - sie bleiben in den Queues und starten frühestens 20:30 Uhr.
Dieses Betriebsmodel ist somit komplementär zu dem Batch-orientierten Betrieb des hww-Rechners CRAY T3E.
Interaktive Jobs
Das Programm wird sofort ausgeführt, sofern die gewünschte Knotenzahl zur Verfügung steht. Knoten für interaktive Programme werden mit dem Befehl isub angefordert. isub belegt Knoten in der .compute Partition, berechnet abhängig von der angeforderten Knotenzahl eine maximal zulässige Laufzeit, startet das parallele Programm, wartet bis die Applikation fertig ist und gibt die Knoten wieder frei. Sollte das Programm nicht in der maximal zulässigen Zeit beendet sein, wird der Rechenlauf abgebrochen (mit SIGTERM und dann 60 Sekunden später mit SIGKILL). Eine genaue Beschreibung erhalten Sie mit man isub
Beispiele
isub -sz 5 my_prog | my_prog läuft auf fünf Knoten |
isub -sz 1000 -rlx my_prog | ..läuft auf soviele Knoten wie möglich |
isub -sz 16 -nt mp my_prog | ..läuft nur auf MP-Knoten |
isub -sz 2 -nt 64mb my_prog | ..läuft nur auf Knoten mit 64 MB |
Beispiel
qsub -lP 54 -lT 5:30:00 myjob
In dem Beispiel werden 54 Knoten für den Job angefordert und die maximale Laufzeit auf fünf Stunden 30 Minuten gesetzt; die Anweisungen befinden sich in der Datei »myjob«. Vom NQS werden die Jobs automatisch je nach angeforderter Knotenzahl und Laufzeit entsprechenden Queues zugeordnet.
Es sind auch drei verschiedene Queues verfügbar, die besondere Eigenschaften haben, z.B. nur MP- oder GP-Knoten benutzen oder kein Zeitlimit besitzen. Somit ist es möglich, wie auch im interaktiven Betrieb mit isub gezielt GP- oder MP-Knoten anzufordern. Wie die MP-Knoten genutzt werden können, finden Sie in [3, 4]. Die Auflistung der verfügbaren Queues und deren Eigenschaften erhält man mit qstat -bl. Um die speziellen Queues benutzen zu können, muß deren Name mit der Option -q dem qsub Befehle übergeben werden.
Beispiel
qsub -lP 16 -q mp64 myjob | läuft nur auf 64-MB MP Knoten |
qsub -lP 16 -q gp32 myjob | läuft nur auf 32-MB GP Knoten |
qsub -lP 16 -q time_bandit myjob | ohne Zeitlimit |
Performance-Messungen sollten interaktiv und nicht im NQS-Betrieb durchgeführt werden, da NQS Jobs bei Bedarf jederzeit von interaktiven Jobs unterbrochen werden können (Gang Scheduling). Das heißt, daß der gesamte Speicherinhalt der von Batch Jobs belegten Knoten auf Plattenperipherie ausgelagert wird. Diese Knoten werden nun für interaktive Jobs benutzt. Wenn diese Knoten wieder frei sind, werden automatisch die ausgelagerten Batch Jobs eingelagert und laufen weiter. Die globale Uhr der Paragon jedoch, die von dclock() und anderen Zeitmessungsroutinen verwendet wird, läuft für alle Jobs weiter, auch für die, die angehalten und ausgelagert wurden.
Durch einen Fehler im NQS werden die login-Dateien nicht durchlaufen. Der Job startet immer in der HOME Directory des Benutzers. Um alle Umgebungsvariable richtig zu setzen, sollten alle Batch Jobs als erste Befehle enthalten:
Für ksh als login Shell
#!/bin/ksh | |||||||||||||||
Vollständiges Beispiel
Das File batch_ex.1 sieht so aus:
#!/bin/ksh |
Dieser Job soll auf 25 Knoten etwa zwei Stunden laufen
qsub -lP 25 -lT 2:30:00 batch_ex.1
Eine genaue Beschreibung erhalten Sie mit man qsub
Status Infos
freepart (fp) | zeigt Partitionen, interaktive bzw. batch Jobs, sowie auch Jobs, die ausgelagert sind (rolled out)
|
qstat -av | zeigt alle NQS Jobs in den Queues an |
qstat -b | zeigt alle verfügbaren Queues an |
Anmerkungen
NQS setzt die Umgebungsvariable NX_DFLT_PART. Vermeiden Sie das automatische Belegen dieser Variablen in Ihren Startup-Dateien (.profile, .cshrc, .login). Fragen Sie gegebenenfalls den System Administrator, wie man die Varaiable NX_DFLT_PART für interaktive Jobs im .profile setzen kann.
Batch Jobs werden mit interaktiven Jobs während des Tages mit Hilfe von »Gang Scheduling« (auch FIFO-Scheduling genannt) abgearbeitet. Da die Paragon als Entwicklungssystem für parallele Programmierung dient, haben interaktive Rechenläufe generell Vorrang.
Wichtig
»Timings« und ähnliche Dinge sollten wegen unserem Usage Model nicht unter NQS gemacht werden!
Bitte beenden Sie Ihre Jobs nicht mit kill -9 oder kill -KILL, sonst verbleibt eine leere Partition, deren Knoten nicht weiter verwendet werden können. Jobs werden wie folgt vorzeitig beendet:
kill -TERM <pid_#> | (interaktive Jobs) |
qdel -k <job_#> | (Batch Jobs) |
Eine genaue Auflistung der Entgeltsätze und Zuordnung der Gebührenklassen finden Sie in der neuen Entgeltordung [5].
| Gebührenklasse | DM / CPU-Stunde und Knoten |
| Auslagenersatz | 0,10 |
| Betriebskosten | 0,40 |
| Selbstkosten Land | 0,65 |
| Vollkosten | 0,90 |
| Marktpreis | 1,00 |
| [1] | intel i860XP Mikroprozessor Data Book, intel Corporation, 1991 | ||
| [2] | Geiger, A., Massively Parallel Supercomputing, BI. 11+12/92 | ||
| [3] | Miller, S., Sihling, D., Geiger, A., intel Paragon MPP: System wurde verdoppelt, BI. 10-12 1996 | ||
| [4] | Miller, S., intel Paragon MPP: Getting the Most from All of the Nodes, BI. 11/12 1997
| [5] | Fischer, E., Preissenkung CPU-Zeit PARAGON XP/S, BI. 3-5 1998
| |
Weitere Informationen finden Sie auf unseren WWW-Server:
http://www.hlrs.de/hpc/platforms
Bernd Krischok, NA-4547
E-Mail: krischok@hlrs.de